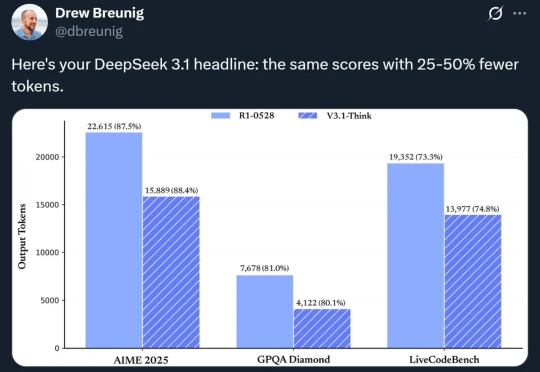
DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费
DeepSeek、GPT-5带头转向混合推理,一个token也不能浪费在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。
来自主题: AI资讯
7774 点击 2025-08-31 13:17
 搜索
搜索
在最近的一档脱口秀节目中,演员张俊调侃 DeepSeek 是一款非常「内耗」的 AI,连个「1 加 1 等于几」都要斟酌半天。
前些天,DeepSeek 在发布 DeepSeek V3.1 的文章评论区中,提及了 UE8M0 FP8 的量化设计,声称是针对即将发布的下一代国产芯片设计。
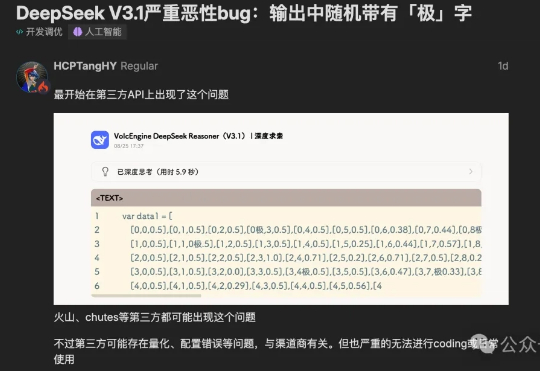
DeepSeek V3.1上演的bug大秀“极你太美”,可谓是让全网热议了一波。 简单来说呢,就是陆续有开发者们发现,当他们在调用API进行代码开发的过程中,输出结果里会时不时蹦出来“极”字。

上周三,DeepSeek 开源了新的基础模型,但不是万众期待的 V4,而是 V3.1-Base,而更早时候,DeepSeek-V3.1 就已经上线了其网页、App 端和小程序。
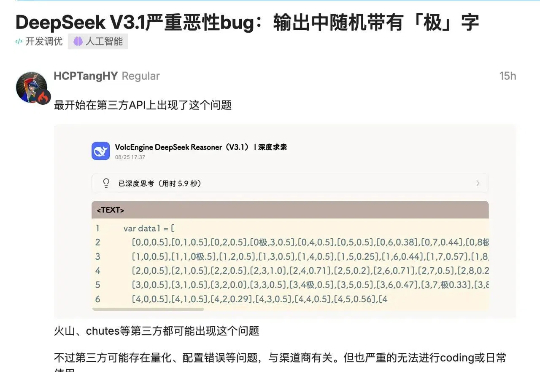
一早起来,看到群里炸了锅!主角是我们备受期待的 DeepSeek V3.1 模型。有用户反馈,该模型在生成文本时,会毫无征兆地随机插入“极”这个汉字(繁体简体都会)
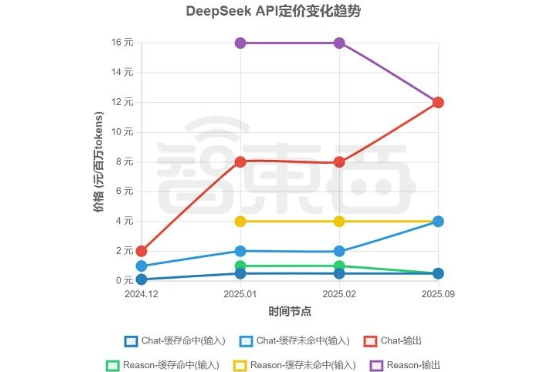
DeepSeek涨价了。 智东西8月23日报道,8月21日,DeepSeek在其公众号官宣了DeepSeek-V3.1的正式发布,还宣布自9月6日起,DeepSeek将执行新价格表,取消了今年2月底推出的夜间优惠,推理与非推理API统一定价,输出价格调整至12元/百万tokens。这一决定,让使用DeepSeek API的最低价格较过去上升了50%。
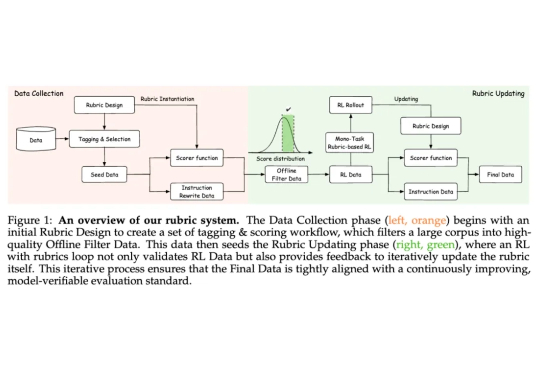
蚂蚁技术研究院联合浙江大学开源全新强化学习范式 Rubicon,通过构建业界最大规模的 10,000+ 条「评分标尺」,成功将强化学习的应用范围拓展至更广阔的主观任务领域。用 5000 样本即超越 671B 模型,让 AI 告别「机械味」。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
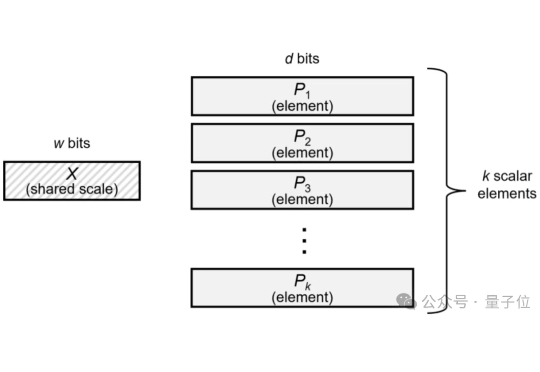
DeepSeek V3.1发布后,一则官方留言让整个AI圈都轰动了,新的架构、下一代国产芯片,总共短短不到20个字,却蕴含了巨大信息量。

今天下午,DeepSeek 官方正式发布 DeepSeek-V3.1。相比于前天只在用户群里通知,今天新增了模型升级点、榜单成绩、model card,huggingface 上现在也可以下载模型文件了。